DeepL や Google 翻訳などの翻訳サービスは、既に人間以上の性能になっており、多くの人々が日常的に使用しています。このような翻訳サービスに使われている予測モデルは、BERT や GPT-3 によって近年精度が格段に上がりました。そして、これらのモデルのベースになっているのが、今回実践する Transformer です。
今回は、その Transformer を使って翻訳モデルを作ります。Transformer のアルゴリズムの詳細に関しては触れないので、気になる方は以下の記事をご覧ください。私も参考にさせていただきました。
今回のコードはこちらにあります。大部分は PyTorch の公式HPのトライアルを参考にしているので、原文が気になる方はこちらをご覧ください。
準備
まず、必要となるモジュールをインポートします。そして、今回使う翻訳データをダウンロードし、取得したデータを学習用に加工します。
必要なモジュールのインポートとディレクトリの設定
今回メインで使う PyTorch 関連のモジュールと torch で言語データを扱うためのモジュールである torchtext をインポートします。両者とも pip を使えばインストールは簡単です。モジュールのインポートのあとは、作成したモデルを保存するためのディレクトリを作ります。
from pathlib import Path import math import time from collections import Counter from tqdm import tqdm import torch import torch.nn as nn from torch import Tensor from torch.nn import ( TransformerEncoder, TransformerDecoder, TransformerEncoderLayer, TransformerDecoderLayer ) from torch.nn.utils.rnn import pad_sequence from torch.utils.data import DataLoader from torchtext.data.utils import get_tokenizer from torchtext.vocab import Vocab from torchtext.utils import download_from_url, extract_archive device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') model_dir_path = Path('model') if not model_dir_path.exists(): model_dir_path.mkdir(parents=True)
学習に使うデータの取得
今回、Transformer を学習させるために使うデータは、ドイツ語と英語のペアーのデータです。これを使い、ドイツ語をモデルに入力したときに、英語を返してくれるモデルを作ります。本当は日本語のデータを使いたかったのですが、Transformer の学習に集中するために、手に入りやすいデータを扱います。
url_base = 'https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/' train_urls = ('train.de.gz', 'train.en.gz') val_urls = ('val.de.gz', 'val.en.gz') file_paths_train = [extract_archive(download_from_url(url_base + url))[0] for url in train_urls] file_paths_valid = [extract_archive(download_from_url(url_base + url))[0] for url in val_urls]
上記のコードを実行すると、指定したURLからドイツ語と英語のデータをダウンロードしてくれます。「file_paths_train」と「file_paths_valid」には、データをダウンロードしたディレクトリのパスが入っているため、このパスを使って取得したデータをロードしていきましょう。
def read_texts(file_path): with open(file_path, 'r') as file: texts = file.readlines() return texts texts_src_train = read_texts(file_paths_train[0]) texts_tgt_train = read_texts(file_paths_train[1]) texts_src_valid = read_texts(file_paths_valid[0]) texts_tgt_valid = read_texts(file_paths_valid[1])
学習用データと検証用データのそれぞれにおいて、入力データと出力データをロードしています。ロードしたデータの中身を確認します。
for src, tgt in zip(texts_src_train[:3], texts_tgt_train[:3]): print(src.strip('\n')) print('↓') print(tgt.strip('\n')) print('')

ドイツ語は理解できませんが、上記を見ると翻訳ペアになっていることが何となく分かるかと思います。これにより翻訳データは手に入れることができましたが、このままでは Transformer で扱えません。Transformer で扱えるようにするためには、テキストを単語で分割し、各単語をインデックスに変換し、数字のベクトルにする必要があるのです。文章にすると一見難しそうに感じますが、torchtext を使えばあっさりできます。
データを学習用の形式に加工する
獲得した翻訳データをディープラーニングで扱える形式に変換します。これを実現するためには、文章を単語に分割し、各単語にユニークなインデックス(数字番号)を振り、文章の各単語をインデックスに置き換えていきます。
まずは、文章を単語に分割するためのツールを用意します。日本語ならば mecab とかが一般的かと思いますが、今回はサクッと行うために、spaCy を使います。spacy モジュールは pip で簡単にインストールできるので、まだの方はインストールしましょう。
python -m spacy download de_core_news_sm python -m spacy download en_core_web_sm
tokenizer_src = get_tokenizer('spacy', language='de_core_news_sm') tokenizer_tgt = get_tokenizer('spacy', language='en_core_web_sm')
上記により、文章をトークン化(単語化)するために必要なツールが手に入りました。日本語において mecab を使う場合は、この部分を変える必要があります。
このツールを使い文章を単語に分割し、単語をインデックス化します。とはいっても、torchtext の Vocab を使えば、簡単にできます。
def build_vocab(texts, tokenizer): counter = Counter() for text in texts: counter.update(tokenizer(text)) return Vocab(counter, specials=['<unk>', '<pad>', '<start>', '<end>']) vocab_src = build_vocab(texts_src_train, tokenizer_src) vocab_tgt = build_vocab(texts_tgt_train, tokenizer_tgt)
上記のコードにより、単語のインデックス化ができました。このコードでは、文章を先程作った tokenizer で単語に分割し、単語の出現回数を数え、それを torchtext の Vocab に突っ込んでいます。こにより、単語のインデックスを簡単に取得できます。この辞書の中身を見てみましょう。
for char, index in list(vocab_src.stoi.items())[:15]: print('Char: {: <8} → Index: {: <2}'.format(char, index))

単語とインデックスで辞書化されており、出現回数が多い順でインデックスが振られています。上記の結果では、「.」「Ein」「einem」の出現回数が多いですね。
テキストをインデックス化し、バッチサイズごとにベクトル化
単語のインデックス辞書が完成したのでこれを使ってテキストの各単語をインデックスに変換していきます。
def data_process(texts_src, texts_tgt, vocab_src, vocab_tgt, tokenizer_src, tokenizer_tgt): data = [] for (src, tgt) in zip(texts_src, texts_tgt): src_tensor = torch.tensor( convert_text_to_indexes(text=src, vocab=vocab_src, tokenizer=tokenizer_src), dtype=torch.long ) tgt_tensor = torch.tensor( convert_text_to_indexes(text=tgt, vocab=vocab_tgt, tokenizer=tokenizer_tgt), dtype=torch.long ) data.append((src_tensor, tgt_tensor)) return data def convert_text_to_indexes(text, vocab, tokenizer): return [vocab['<start>']] + [ vocab[token] for token in tokenizer(text.strip("\n")) ] + [vocab['<end>']] train_data = data_process( texts_src=texts_src_train, texts_tgt=texts_tgt_train, vocab_src=vocab_src, vocab_tgt=vocab_tgt, tokenizer_src=tokenizer_src, tokenizer_tgt=tokenizer_tgt ) valid_data = data_process( texts_src=texts_src_valid, texts_tgt=texts_tgt_valid, vocab_src=vocab_src, vocab_tgt=vocab_tgt, tokenizer_src=tokenizer_src, tokenizer_tgt=tokenizer_tgt )
関数を2つ作ったので、パット見ではわかりづらくなりましたが、やっていることは簡単です。Transformer への入力テキストと出力テキストをそれぞれの単語インデックス辞書を使って、インデックス列に変換し、リストに順番に追加しています。ここで出来上がった変数の中身を見てみましょう。
print('インデックス化された文章') print('Input: {}\nOutput: {}'.format(train_data[0][0], train_data[0][1])) print('') print('インデックス化された文章をもとに戻す') print('Input: {}\nOutput: {}'.format( ' '.join([vocab_src.itos[x] for x in train_data[0][0]]), ' '.join([vocab_tgt.itos[x] for x in train_data[0][1]]) ))

文章がインデックスのベクトルになっていることがわかります。また、そのインデックスベクトルを元の文章に戻すことも簡単にできていますね。
文章のインデックス化は完成したので、データの加工の最後の処理である、バッチ化を行います。Transformer を学習させるときは、翻訳データのペアを1件ずつ学習させるよりは、何件かをまとめて学習させた方が、モデルの汎化性能が高まります。過学習対策です。これは、torch の DataLoader を使ってサクッとやります。
batch_size = 128 PAD_IDX = vocab_src['<pad>'] START_IDX = vocab_src['<start>'] END_IDX = vocab_src['<end>'] def generate_batch(data_batch): batch_src, batch_tgt = [], [] for src, tgt in data_batch: batch_src.append(src) batch_tgt.append(tgt) batch_src = pad_sequence(batch_src, padding_value=PAD_IDX) batch_tgt = pad_sequence(batch_tgt, padding_value=PAD_IDX) return batch_src, batch_tgt train_iter = DataLoader(train_data, batch_size=batch_size, shuffle=True, collate_fn=generate_batch) valid_iter = DataLoader(valid_data, batch_size=batch_size, shuffle=True, collate_fn=generate_batch)
先程作ったインデックスベクトルを指定したバッチサイズでまとめて行列にしています。この際に行列にするために、短い文章に対しては PAD_IDX のインデックスで埋めています。作成したデータの中身を見てみます。
list(train_iter)[0]

上の図を見てもらえば分かる通り、各列が各文章に対応しています。なので、1行目は各列とも
Transformer を使った翻訳モデルの設計
学習データ用の翻訳データの準備が終わったので、このデータを使ってTransformer を使った翻訳モデルを作っていきます。ただ、これを行うためには、予めモデルを設計しておかなければいけません。なので、ここでは先に翻訳モデルの設計をします。モデルの設計は class 化して行うので、複数のクラスが出てきて分かりづらいかもしれません。そこはご容赦お願いします。
翻訳モデル全体のクラス
以下のクラスが翻訳モデルの全体のクラスです。PyTorch で作成したモデルを理解する上で、注視すべきは「forward 関数」です。この関数がデータを引数として受け取って、定義した処理を行ったあと、出力データとして結果を返します。なので、この関数を見ればモデルがどのような処理をしているのかがわかります。以下のコードでは、次のような順番で処理を行っています。
- 入力データ(単語インデックスの行列)を Embedding
- 1. に positional_encoding を追加
- 2. を TransformerEncoderLayer の入力データとして与える
- 出力データを Embedding
- 4. に positional_encoding を追加
- 3. と 4. と入力データのマスキングを を TransformerDecoderLayer の入力として与える
- 6. に全層結合を追加して、結果を出力
class Seq2SeqTransformer(nn.Module): def __init__( self, num_encoder_layers: int, num_decoder_layers: int, embedding_size: int, vocab_size_src: int, vocab_size_tgt: int, dim_feedforward:int = 512, dropout:float = 0.1, nhead:int = 8 ): super(Seq2SeqTransformer, self).__init__() self.token_embedding_src = TokenEmbedding(vocab_size_src, embedding_size) self.positional_encoding = PositionalEncoding(embedding_size, dropout=dropout) encoder_layer = TransformerEncoderLayer( d_model=embedding_size, nhead=nhead, dim_feedforward=dim_feedforward ) self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers) self.token_embedding_tgt = TokenEmbedding(vocab_size_tgt, embedding_size) decoder_layer = TransformerDecoderLayer( d_model=embedding_size, nhead=nhead, dim_feedforward=dim_feedforward ) self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers) self.output = nn.Linear(embedding_size, vocab_size_tgt) def forward( self, src: Tensor, tgt: Tensor, mask_src: Tensor, mask_tgt: Tensor, padding_mask_src: Tensor, padding_mask_tgt: Tensor, memory_key_padding_mask: Tensor ): embedding_src = self.positional_encoding(self.token_embedding_src(src)) memory = self.transformer_encoder(embedding_src, mask_src, padding_mask_src) embedding_tgt = self.positional_encoding(self.token_embedding_tgt(tgt)) outs = self.transformer_decoder( embedding_tgt, memory, mask_tgt, None, padding_mask_tgt, memory_key_padding_mask ) return self.output(outs) def encode(self, src: Tensor, mask_src: Tensor): return self.transformer_encoder(self.positional_encoding(self.token_embedding_src(src)), mask_src) def decode(self, tgt: Tensor, memory: Tensor, mask_tgt: Tensor): return self.transformer_decoder(self.positional_encoding(self.token_embedding_tgt(tgt)), memory, mask_tgt)
Embedding と PositionalEncoding のクラス
自然言語処理データをディープラーニングで扱うために必ずやると言っても良い、 Embedding のクラスを定義しています。Encoder と Decoder の両方の入力データに対して Embedding を行うので、クラス化しています。
class TokenEmbedding(nn.Module): def __init__(self, vocab_size, embedding_size): super(TokenEmbedding, self).__init__() self.embedding = nn.Embedding(vocab_size, embedding_size) self.embedding_size = embedding_size def forward(self, tokens: Tensor): return self.embedding(tokens.long()) * math.sqrt(self.embedding_size)
PositionalEncoding は見慣れないかもしれませんが、これは Embedding 化されたデータが、文章の何文字目かをわかるようにするためのものです。maxlen 引数は予め用意する文章の長さを表しています。
class PositionalEncoding(nn.Module): def __init__(self, embedding_size: int, dropout: float, maxlen: int = 5000): super(PositionalEncoding, self).__init__() den = torch.exp(-torch.arange(0, embedding_size, 2) * math.log(10000) / embedding_size) pos = torch.arange(0, maxlen).reshape(maxlen, 1) embedding_pos = torch.zeros((maxlen, embedding_size)) embedding_pos[:, 0::2] = torch.sin(pos * den) embedding_pos[:, 1::2] = torch.cos(pos * den) embedding_pos = embedding_pos.unsqueeze(-2) self.dropout = nn.Dropout(dropout) self.register_buffer('embedding_pos', embedding_pos) def forward(self, token_embedding: Tensor): return self.dropout(token_embedding + self.embedding_pos[: token_embedding.size(0), :])
マスキング
Transformer のモデルでは、出力データも使って学習させるため、何も処理をしなければ答えを知った上で答えを導き出すというチート状態になってしまいます。本来使いたいデータは、予測する◯文字目の1文字前までの結果であるため、◯文字目以降の出力データがモデルに入力されないようにマスクする必要があります。
def create_mask(src, tgt, PAD_IDX): seq_len_src = src.shape[0] seq_len_tgt = tgt.shape[0] mask_tgt = generate_square_subsequent_mask(seq_len_tgt) mask_src = torch.zeros((seq_len_src, seq_len_src), device=device).type(torch.bool) padding_mask_src = (src == PAD_IDX).transpose(0, 1) padding_mask_tgt = (tgt == PAD_IDX).transpose(0, 1) return mask_src, mask_tgt, padding_mask_src, padding_mask_tgt def generate_square_subsequent_mask(seq_len, PAD_IDX): mask = (torch.triu(torch.ones((seq_len, seq_len), device=device)) == 1).transpose(0, 1) mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == PAD_IDX, float(0.0)) return mask
以上で、Transformer を使った翻訳モデルの設計は完了です。あとは、モデルのインスタンスを作成すれば、翻訳モデルを学習することができます。
Transformer を使った翻訳モデルの学習
これまでの話で、翻訳モデルのインスタンスを作るための class 定義が終わったので、モデルのインスタンスを作成し、翻訳データを使ってモデルを学習させていきます。そのために、先にモデルの学習と評価の関数を定義します。
モデルの学習と評価の関数の定義
モデルの学習と評価の関数を先に定義しておきます。この2つを関数化することで、実際の学習のループ処理のコードが見やすくなります。とはいっても、学習と評価の関数のコードはさほど難しくないでしょう。両者は、パラメータの更新を行うか否かの違いだけであり、それ以外の処理の流れは共通しています。共通している部分では、バッチサイズ分のデータごとに、入力データ、出力データ、マスキングをモデルに与え、モデルの出力結果を獲得し、その結果と教師データを評価関数に与え、損失値を得ています。
def train(model, data, optimizer, criterion, PAD_IDX): model.train() losses = 0 for src, tgt in tqdm(data): src = src.to(device) tgt = tgt.to(device) input_tgt = tgt[:-1, :] mask_src, mask_tgt, padding_mask_src, padding_mask_tgt = create_mask(src, input_tgt, PAD_IDX) logits = model( src=src, tgt=input_tgt, mask_src=mask_src, mask_tgt=mask_tgt, padding_mask_src=padding_mask_src, padding_mask_tgt=padding_mask_tgt, memory_key_padding_mask=padding_mask_src ) optimizer.zero_grad() output_tgt = tgt[1:, :] loss = criterion(logits.reshape(-1, logits.shape[-1]), output_tgt.reshape(-1)) loss.backward() optimizer.step() losses += loss.item() return losses / len(data) def evaluate(model, data, criterion, PAD_IDX): model.eval() losses = 0 for src, tgt in data: src = src.to(device) tgt = tgt.to(device) input_tgt = tgt[:-1, :] mask_src, mask_tgt, padding_mask_src, padding_mask_tgt = create_mask(src, input_tgt, PAD_IDX) logits = model( src=src, tgt=input_tgt, mask_src=mask_src, mask_tgt=mask_tgt, padding_mask_src=padding_mask_src, padding_mask_tgt=padding_mask_tgt, memory_key_padding_mask=padding_mask_src ) output_tgt = tgt[1:, :] loss = criterion(logits.reshape(-1, logits.shape[-1]), output_tgt.reshape(-1)) losses += loss.item() return losses / len(data)
モデルのインスタンスの作成
モデルのインスタンス、評価関数と最適化関数を定義しています。モデルのレイヤーサイズに関しては、マシンスペックに応じて変えるのが良いでしょう。筆者の場合は、論文の設定からレイヤーサイズをだいぶ少なくしました。
vocab_size_src = len(vocab_src) vocab_size_tgt = len(vocab_tgt) embedding_size = 240 nhead = 8 dim_feedforward = 100 num_encoder_layers = 2 num_decoder_layers = 2 dropout = 0.1 model = Seq2SeqTransformer( num_encoder_layers=num_encoder_layers, num_decoder_layers=num_decoder_layers, embedding_size=embedding_size, vocab_size_src=vocab_size_src, vocab_size_tgt=vocab_size_tgt, dim_feedforward=dim_feedforward, dropout=dropout, nhead=nhead ) for p in model.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p) model = model.to(device) criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX) optimizer = torch.optim.Adam(model.parameters())
モデルの学習
なんだかんだでここまで長くなってしまいましたが、遂にモデルの学習に入れます。以下のコードでは、指定した回数分(epoch)学習を行っており、patience 回の損失値の更新がなければ学習処理を終わらせるようにしています。実際の学習処理は先程指定した関数内で行っているので、ここではその関数を呼び出すだけです。
epoch = 100 best_loss = float('Inf') best_model = None patience = 10 counter = 0 for loop in range(1, epoch + 1): start_time = time.time() loss_train = train( model=model, data=train_iter, optimizer=optimizer, criterion=criterion, PAD_IDX=PAD_IDX ) elapsed_time = time.time() - start_time loss_valid = evaluate( model=model, data=valid_iter, criterion=criterion, PAD_IDX=PAD_IDX ) print('[{}/{}] train loss: {:.2f}, valid loss: {:.2f} [{}{:.0f}s] count: {}, {}'.format( loop, epoch, loss_train, loss_valid, str(int(math.floor(elapsed_time / 60))) + 'm' if math.floor(elapsed_time / 60) > 0 else '', elapsed_time % 60, counter, '**' if best_loss > loss_valid else '' )) if best_loss > loss_valid: best_loss = loss_valid best_model = model counter = 0 if counter > patience: break counter += 1
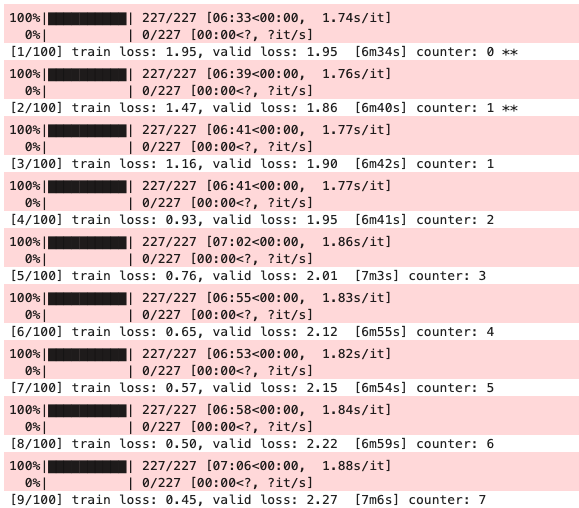
上記の結果を見ると、早い段階で損失値が更新されていないことがわかります。まだまだ改善できる余地がありそうですが、ハイパーパラメータの探索までやっていると長くなりすぎるので、別の機会に書きたいと思います。
モデルの保存
モデルの学習が終わったのですぐさま翻訳を試したいところですが、学習したモデルの保存は忘れずやっておきましょう。これをしておけば、今後学習済みのモデルをすぐさま使えます。
torch.save(best_model.state_dict(), model_dir_path.joinpath('translation_transfomer.pth'))
翻訳の実行
学習した翻訳モデルを使って、実際に翻訳をします。学習したモデルに対して翻訳したいテキストを与えて、翻訳の結果を受け取ります。内部では、学習したモデルが出力した結果を decoder の input として順々に追加して、これまでの予測結果を踏まえた時系列処理を行っています。
def translate( model, text, vocab_src, vocab_tgt, tokenizer_src, seq_len_tgt, START_IDX, END_IDX ): model.eval() tokens = convert_text_to_indexes(text=text, vocab=vocab_src, tokenizer=tokenizer_src) num_tokens = len(tokens) src = torch.LongTensor(tokens).reshape(num_tokens, 1) mask_src = (torch.zeros(num_tokens, num_tokens)).type(torch.bool) predicts = greedy_decode( model=model, src=src, mask_src=mask_src, seq_len_tgt=seq_len_tgt, START_IDX=START_IDX, END_IDX=END_IDX ).flatten() return ' '.join([vocab_tgt.itos[token] for token in predicts]).replace("<start>", "").replace("<end>", "") def greedy_decode(model, src, mask_src, seq_len_tgt, START_IDX, END_IDX): src = src.to(device) mask_src = mask_src.to(device) memory = model.encode(src, mask_src) memory = model.transformer_encoder(model.positional_encoding(model.token_embedding_src(src)), mask_src) ys = torch.ones(1, 1).fill_(START_IDX).type(torch.long).to(device) for i in range(seq_len_tgt - 1): memory = memory.to(device) memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool) mask_tgt = (generate_square_subsequent_mask(ys.size(0)).type(torch.bool)).to(device) output = model.decode(ys, memory, mask_tgt) output = output.transpose(0, 1) output = model.output(output[:, -1]) _, next_word = torch.max(output, dim = 1) next_word = next_word.item() ys = torch.cat([ys, torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0) if next_word == END_IDX: break return ys
上記で定義した関数に対して、翻訳したいテキストと学習済みモデルを与えれば、翻訳結果を獲得できます。
seq_len_tgt = max([len(x[1]) for x in train_data]) text = 'Eine Gruppe von Menschen steht vor einem Iglu .' translate( model=best_model, text=text, vocab_src=vocab_src, vocab_tgt=vocab_tgt, tokenizer_src=tokenizer_src, seq_len_tgt=seq_len_tgt, START_IDX=START_IDX, END_IDX=END_IDX )
![]()
今回翻訳したドイツ語は日本語に訳すと「イグルーの前に立つ人々のグループ」(Google翻訳の結果)だそうです。予測結果を見ると、「stand」が三人称単数形になっていないという惜しい結果ではありましたが、それ以外は完璧でしょう。論文のモデルサイズよりはだいぶ小さいですが、かなりの精度のモデルができそうです。
終わりに
今回は PyTorch を使って翻訳モデルを作りましたが、PyTorch を使えば、画像や音に対する予測モデルも作れます。ただ、ディープラーニングのモデルは、何をしているかを理解するのが大変です。しかし、以下の本はコードを実践しながらやっていることを理解するのに最適かと思うので、気になる方はご覧ください。
