同じ話を何度も聴くたびに同じように愛想笑いをするのは心が無になりますよね。まるで魔法少女まどかマギカの世界のように、繰り返されるたびに絶望感を感じます。そういうときは、録音した音声を一語一句テキスト化し、全く同じ話をしていることを認識してもらえば良いと思います。
しかしながら、聞きながらタイピングしてテキストに起こすのは、いかにも残してやろう感が満載であり、心証は良くないですね。それに、話している方はインタビューされている気分でより饒舌になり、話がなかなか終わらなくなるかもしれません。そんなときにうってつけなのが、スマフォなどに搭載されている音声入力です。
これはディープラーニングのモデルを使って実現しています。そこで、今回は音声のテキスト化(Speech to Text)の最先端のモデルであるGoogle Cloud Platform(以下、GCP)のAPIを使って実装してみます。実装するにあたっては、音声のテキスト化を順次出力すればよいのですが、せっかくなので、GUIを使って音声認識のON/OFFをやりやすいようにします。
今回のコードはこちら(GitHub)に置いてあります。実行すると、以下の結果が得られます。

準備
早速音声をテキスト化するプログラムを実装していきたいのですが、今回はGCPのAPIを使うため、これを使えるようにしなければいけません。そのためには、GCPのWebページでこのAPIを有効にする必要があります。
この記事では、実際に画面上にストリーミングでの音声のテキスト化を実装するところに重点を置くため、GCPでの設定と認証に関しては以下Webページを御覧ください。
qiita.com
ストリーミングで音声のテキスト化を実装
それでは、Speech to Text APIを使って音声ストリーミングをテキスト化し、GUIでON/OFFが簡単に切り替えられるようにするプログラムを作っていきます。2つ同時に話すと理解しづらくなるので、まずはGUIなしでSpeech to Textを実行できるようにします。この部分のコードはこちらです。
Specch to Text APIを使った音声のテキスト化の実行
Speech to Textを実装するにあたっては、以下の本家Googleドキュメントを参考にさせていただきました。今回作成したプログラムは必要最低限な部分だけに絞っています。
https://github.com/GoogleCloudPlatform/python-docs-samples/blob/master/speech/microphone/transcribe_streaming_infinite.pygithub.com
Importと設定
まず、必要なモジュールのimportと変数の設定をします。必要なモジュールは、GCPのSpeech to Text APIをたたくための『google.cloud』、マイクから音声を入力する『pyaudio』、入力した音声を格納していく「queue」です。
from six.moves import queue import pyaudio from google.cloud import speech from google.cloud.speech import enums from google.cloud.speech import types stream_close = False # ストリーミング終了時にTrueとなる STREAMING_LIMIT = 240000 SAMPLE_RATE = 16000 CHUNK_SIZE = int(SAMPLE_RATE / 10)
マイクから音声入力をするためのクラス
主要部分は、pyaudio.PyAudio()により音声を扱うインスタンスを作っているところです。このインスタンスの関数openをchannels引数に1を与えて実行することで、マイクから入力した音声を拾ってくれます。
generate関数内で、取得した音声をキューに逐次格納しています。
class ResumableMicrophoneStream: def __init__(self, rate, chunk_size): self._rate = rate self.chunk_size = chunk_size self._num_channels = 1 # 取得した音声を格納するキュー self._buff = queue.Queue() # マイクから音声を入力するインスタンス self._audio_interface = pyaudio.PyAudio() self._audio_stream = self._audio_interface.open( format=pyaudio.paInt16, channels=self._num_channels, rate=self._rate, input=True, frames_per_buffer=self.chunk_size, stream_callback=self._fill_buffer, ) # with文実行時に呼ばれる def __enter__(self): global stream_close stream_close = False return self # with文終了時に呼ばれる def __exit__(self, type, value, traceback): self._audio_stream.stop_stream() self._audio_stream.close() self._buff.put(None) self._audio_interface.terminate() global stream_close stream_close = True def _fill_buffer(self, in_data, *args, **kwargs): # マイクから入力した音声をキューに格納する self._buff.put(in_data) return None, pyaudio.paContinue def generator(self): global stream_close while not stream_close: data = [] chunk = self._buff.get() if chunk is None: return data.append(chunk) # キューが空になるまでdataリストに追加する while True: try: chunk = self._buff.get(block=False) if chunk is None: return data.append(chunk) except queue.Empty: break yield b''.join(data)
Speech to Textの結果の表示
responsesインスタンスの中に音声をテキスト化した結果がJson形式で入っています。これを順次表示させています。このとき、result.is_finalがTrueになっていると文末と判断しており、Falseの場合はまだ文の途中です。この条件で分岐させて、文途中の場合は文頭に空白を入れてわかるようにしています。
『エンド』といったら終了するように、stream_close変数をTrueにしています。
## 音声のテキスト化を表示する関数 def listen_print_loop(responses, stream): global stream_close for response in responses: if not response.results: continue result = response.results[0] if not result.alternatives: continue transcript = result.alternatives[0].transcript # 文末と判定したら区切る if result.is_final: print(transcript) else: print(' ', transcript) # 『エンド』を言うと終了する if transcript == 'エンド': stream_close = True
Speech to Textの実行
上記のプログラムを組み合わせることでSpeech to Textを実行します。プログラムの流れとしては、GoogleのSpeech to Text APIの認証を行い、Webマイクから入力できるようにし、音声をテキスト化しています。それぞれの関数を実行しているだけなので、流れ作業ですね。
あとは、この関数をmainから実行すれば、すぐに遊べます。
## Speech to Textを実行する関数 def excecute_speech_to_text_streaming(): print('Start Speech to Text Streaming') client = speech.SpeechClient() config = speech.types.RecognitionConfig( encoding=speech.enums.RecognitionConfig.AudioEncoding.LINEAR16, sample_rate_hertz=SAMPLE_RATE, language_code='ja-JP', max_alternatives=1 ) streaming_config = speech.types.StreamingRecognitionConfig( config=config, interim_results=True ) mic_manager = ResumableMicrophoneStream(SAMPLE_RATE, CHUNK_SIZE) with mic_manager as stream: # マイクから入力した音声の取得 audio_generator = stream.generator() requests = ( speech.types.StreamingRecognizeRequest(audio_content=content) for content in audio_generator ) # Google Speech to Text APIを使って音声をテキストに変換 responses = client.streaming_recognize( streaming_config, requests ) # テキスト変換結果を表示する listen_print_loop(responses, stream) print('End Speech to Text Streaming')
実行結果
以下の結果を見て分かる通り、文の途中ではテキスト化された文章が順次変わっており、文末だと判断したら一文が決定されています。音声の一部分だけでテキスト化しているのではなく、音声の時系列を汲み取ってテキスト化しているので、より正確な音声認識になっています。翻訳スピードも申し分なく、さすがGoogleですね。
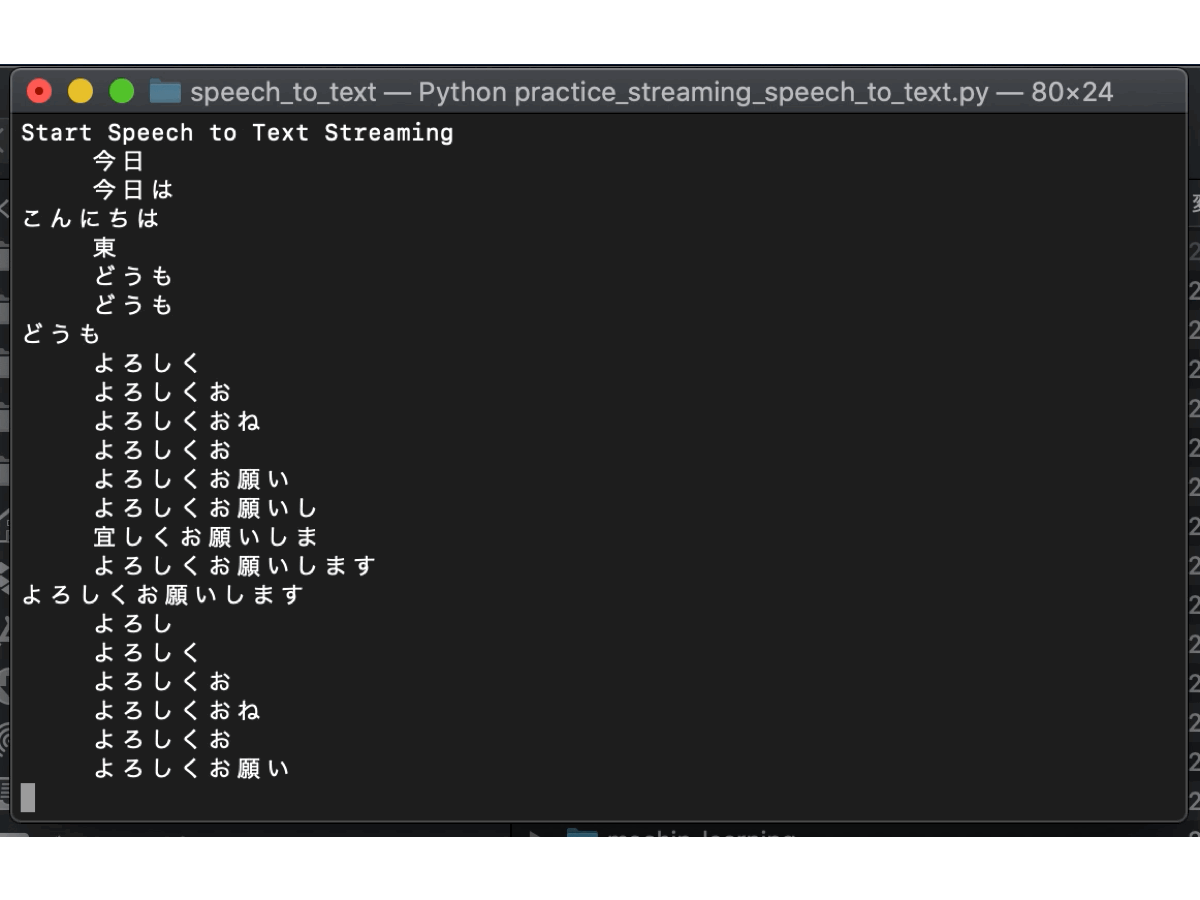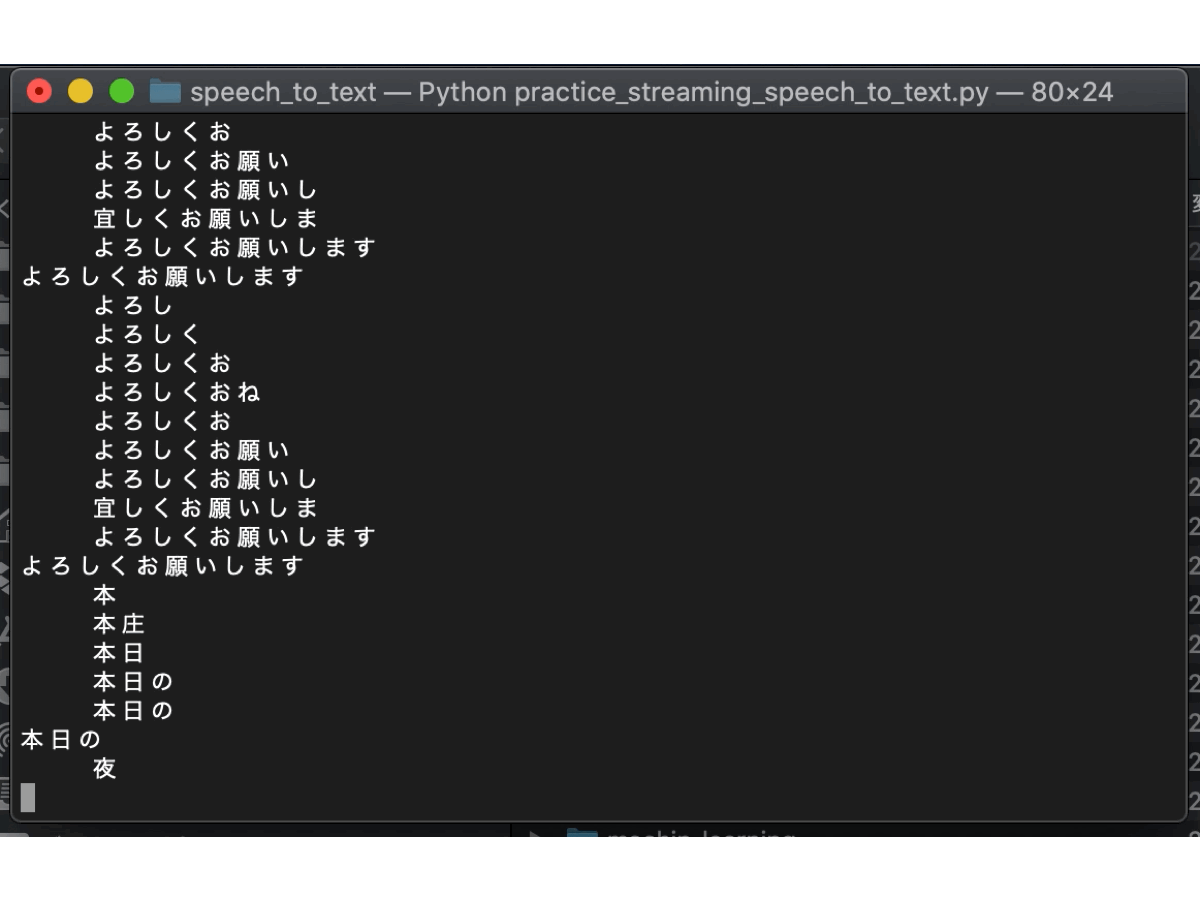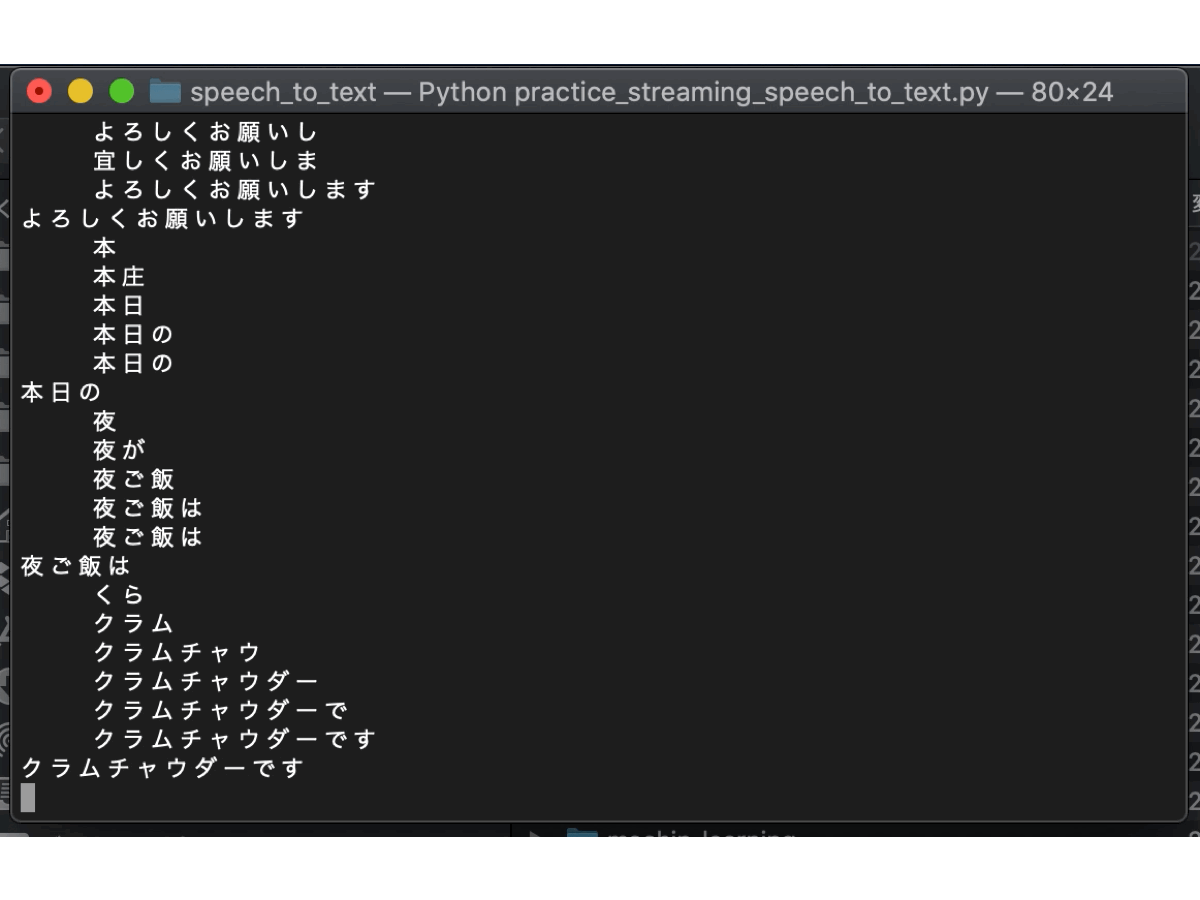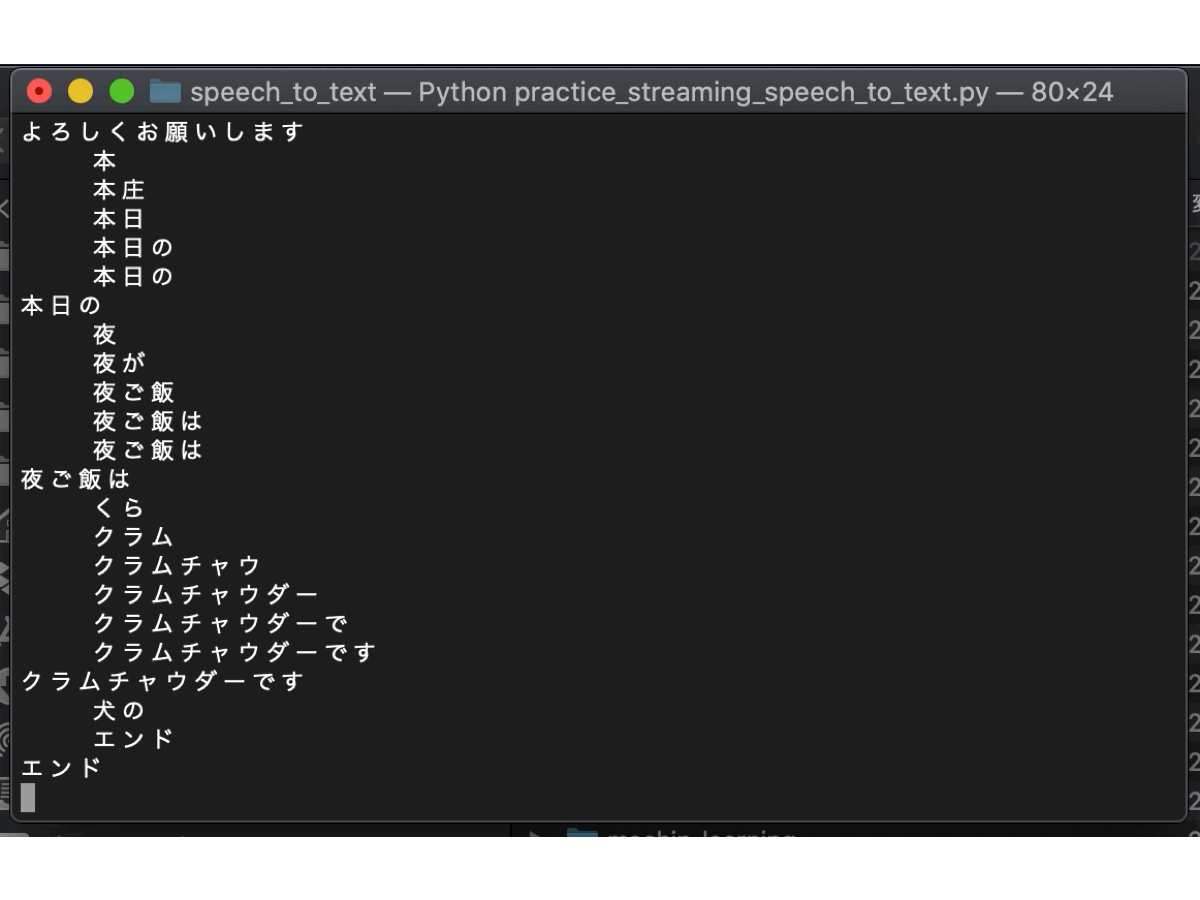
以上で、ストリーミングによるSpeech to Textの実行は完了しました。これで終わりでもよいのですが、『エンド』と言ったときに終了としているため、『エンド』という言葉を文章内で使えなくなってしまいました。そこで、GUIによりSpeech to Textの開始と終了を制御していきます。
GUIによるSpeech to Textの制御
上記まででストリーミングでのSpeech to Textの実装はできるようになりました。Googleが提供するAPIということもあって、時系列での意味を含んだ音声のテキスト化を実現できています。しかし、APIというよりは、これを実装する上では制御の方に課題があります。それは、開始と終了を制御できないことです。そこで、GUIからSpeech to Textを実行するようにして、この課題を解決します。フィギュアスケートの選手とコーチの関係性のように、コーチから外で見てもらうことで名選手になるわけですね。
GUIの雛形を作る
それでは、GUIを構築していきますが、今回はGUI作成用のモジュールとして『Kivy』を使いました。PythonでGUIを作るにはいくつかモジュールがありますが、最近はKivyは人気のようです。Kivyの基本的な使い方に関しては、以下のサイトが参考になります。
qiita.com
それでは、Kivyを使って今回作るGUIの雛形を作っていきます。方針としては、開始と終了ボタンがあり、Speech to Textの結果が複数行文表示されることです。また、Kivyでは、画面の設計と画面処理は分けて書きます。画面構成をKivyファイルに書き、画面処理をPythonファイルに記載します。GUIだけを簡易に実行するコードはこちら(GitHub)です。
まずは画面処理の方を先に見ていきます。
GUIでの画面処理
先に必要なモジュールをimportしていますが、以下の処理内では、画面サイズの設定と日本語を扱えるようにする設定もしています。デフォルトでは、日本語が文字化けするので、日本語のフォントを設定することで文字化けを解消します。使用したフォントはこちらから入手しました。ここにあるフォントを実行ファイルと同じディレクトリに入れれば使うことができます。LabelBase.register関数でデフォルトのフォントを指定しています。
from kivy.config import Config # 画面サイズを決める Config.set('graphics', 'width', str(1000)) Config.set('graphics', 'height', str(300)) from kivy.app import App from kivy.uix.label import Label from kivy.uix.widget import Widget from kivy.core.text import LabelBase, DEFAULT_FONT from kivy.properties import StringProperty LabelBase.register(DEFAULT_FONT, 'ipaexg.ttf')
次に、GUIを表示し、ボタンをクリックした場合の処理を実行する部分を書きます。
- SpeechToTextクラス:ウィンドウのタイトルとボタン処理を制御するクラスTextWidgetを呼び出すクラス
- TextWidgetクラス:ボタン処理を制御するクラス
class SpeechToTextApp(App): def __init__(self, **kwargs): super(SpeechToTextApp, self).__init__(**kwargs) self.title = 'Speech to Text' # ウィンドウの名前を変更 def build(self): text_widget = TextWidget() return text_widget class TextWidget(Widget): text = StringProperty() def __init__(self, **kwargs): super(TextWidget, self).__init__(**kwargs) self.text = '' self.number = 0 ## 開始ボタンを押したときの処理を行う関数 def buttonClickedStart(self): self.text = 'やったるぜぃ' ## 終了ボタンを押したときの処理を行う関数 def buttonClickedEnd(self): self.text = '' if __name__ == '__main__': SpeechToTextApp().run()
画面処理の部分に関しては完成しましたが、画面構成がまだできていません。Kivyモジュールでは、GUIを起動するクラスと同名のKivyファイルを作ることで、プログラム実行時に自動的にロードしてくれます。
GUIでの画面構成
今回のGUIでの画面構成は開始と終了のボタンとテキスト表示になります。BoxtLayoutでテキスト表示領域とボタンの表示領域を分けています。その際に、size_hint_y: 0.2を指定して、テキスト表示領域とボタン表示領域を8:2にしています。ボタン表示領域内でBoxLayoutを更に定義することで、ボタン表示領域内で開始ボタンと終了ボタンの表示領域を定義しています。まとめると、以下のようになります。
#-*- coding: utf-8 -*-
TextWidget:
<TextWidget>:
BoxLayout:
orientation: 'vertical'
size: root.size
Label:
text_size: self.size
id: label1
font_size: 50
text: root.text
halign: 'left'
valign: 'top'
padding_x: 35
padding_y: 20
BoxLayout:
size_hint_y: 0.2
padding: 30,30,30,10
Button:
id: button_start
text: '開始'
font_size: 30
on_press: root.buttonClickedStart()
Button:
id: button_end
text: '終了'
font_size: 30
on_press: root.buttonClickedEnd()
GUIの実行
上記のコードでGUIの画面処理と画面構成が完了したので、実行してみます。開始ボタンを押すと指定した言葉が表示され、終了ボタンを押すと消えます。

以上でGUIの簡単な実行は終了です。いよいよ、次の章において今回の記事の最後であるGUIを使ったストリーミングでのSpeech to Textを実装します。
GUIを使ったストリーミングによるSpeech to Textの実行
これまでのコードで、Speech to TextとGUIは別々に実装することができました。ここでは、この2つをあわせて、GUIを使ったストリーミングによるSpeech to Textを完成させます。この2つを併せたコードはこちら(GitHub)です。
これまで作成したコードで修正したのは、大きくは以下の部分です。
- Speech to Textの結果をspeech_to_text_listリストに格納
- 開始ボタンを押したときに、別スレッドを立ててSpeech to Textを実行
- 終了ボタンを押したときに、テキスト表示領域を空文字にして、これまでの結果をファイルに書き込む
- speech_to_text_listに格納されている文のリストから指定た行数文を取得するdisplay_texts関数の追加
from pathlib import Path import pyaudio from six.moves import queue from kivy.config import Config from kivy.app import App from kivy.uix.label import Label from kivy.uix.widget import Widget from kivy.core.text import LabelBase, DEFAULT_FONT from kivy.properties import StringProperty from kivy.uix.boxlayout import BoxLayout from google.cloud import speech from google.cloud.speech import enums from google.cloud.speech import types import threading # GUI Windowの画面サイズ Config.set('graphics', 'width', str(1000)) Config.set('graphics', 'height', str(300)) STREAMING_LIMIT = 240000 SAMPLE_RATE = 16000 CHUNK_SIZE = int(SAMPLE_RATE / 10) LabelBase.register(DEFAULT_FONT, 'ipaexg.ttf') speech_to_text_list = [] stream_close = False recordinng_data_dir_path = Path('recording_data') if not recordinng_data_dir_path.exists(): recordinng_data_dir_path.mkdir(parents=True) class TextWidget(Widget): text = StringProperty() def __init__(self, **kwargs): super(TextWidget, self).__init__(**kwargs) self.text = '' self.number = 0 ## 開始ボタンを押したときの処理を行う関数 def buttonClickedStart(self): t1 = threading.Thread(target=excecute_speech_to_text_streaming, args=(self,)) t1.start() ## 終了ボタンを押したときの処理を行う関数 def buttonClickedEnd(self): global stream_close global speech_to_text_list stream_close = True with open(recordinng_data_dir_path.joinpath('streaming_result.txt'), 'w' ) as file: text = '\n'.join(speech_to_text_list) file.writelines(text) self.text = '' speech_to_text_list = [] def update(self): self.text = display_texts(max_n_text=6) class SpeechToTextApp(App): def __init__(self, **kwargs): super(SpeechToTextApp, self).__init__(**kwargs) self.title = 'Speech to Text' # ウィンドウの名前を変更 def build(self): text_widget = TextWidget() return text_widget ## 取得した音声テキストから直近の指定行数文を一つの改行付きの1つのテキストにする関数 def display_texts(max_n_text=5): if len(speech_to_text_list) <= max_n_text: text = '\n'.join(speech_to_text_list) else: text = '\n'.join(speech_to_text_list[-max_n_text:]) return text class ResumableMicrophoneStream: def __init__(self, rate, chunk_size): self._rate = rate self.chunk_size = chunk_size self._num_channels = 1 self._buff = queue.Queue() self._audio_interface = pyaudio.PyAudio() self._audio_stream = self._audio_interface.open( format=pyaudio.paInt16, channels=self._num_channels, rate=self._rate, input=True, frames_per_buffer=self.chunk_size, stream_callback=self._fill_buffer, ) def __enter__(self): global stream_close stream_close = False return self def __exit__(self, type, value, traceback): self._audio_stream.stop_stream() self._audio_stream.close() self._buff.put(None) self._audio_interface.terminate() global stream_close stream_close = True def _fill_buffer(self, in_data, *args, **kwargs): self._buff.put(in_data) return None, pyaudio.paContinue def generator(self): global stream_close while not stream_close: data = [] chunk = self._buff.get() if chunk is None: return data.append(chunk) # キューがからになるまで繰り返す while True: try: chunk = self._buff.get(block=False) if chunk is None: return data.append(chunk) except queue.Empty: break yield b''.join(data) def listen_print_loop(responses, stream, text_widget): global stream_close global speech_to_text_list for response in responses: if stream_close: break if not response.results: continue result = response.results[0] if not result.alternatives: continue transcript = result.alternatives[0].transcript if result.is_final: speech_to_text_list[-1] = transcript stream.last_transcript_was_final = True else: if len(speech_to_text_list) == 0: speech_to_text_list.append(transcript) else: if stream.last_transcript_was_final: speech_to_text_list.append(transcript) else: speech_to_text_list[-1] = transcript stream.last_transcript_was_final = False text_widget.update() def excecute_speech_to_text_streaming(text_widget): print('Start Speech to Text Streaming') client = speech.SpeechClient() config = speech.types.RecognitionConfig( encoding=speech.enums.RecognitionConfig.AudioEncoding.LINEAR16, sample_rate_hertz=SAMPLE_RATE, language_code='ja-JP', max_alternatives=1 ) streaming_config = speech.types.StreamingRecognitionConfig( config=config, interim_results=True ) mic_manager = ResumableMicrophoneStream(SAMPLE_RATE, CHUNK_SIZE) with mic_manager as stream: audio_generator = stream.generator() requests = ( speech.types.StreamingRecognizeRequest(audio_content=content) for content in audio_generator ) responses = client.streaming_recognize( streaming_config, requests ) listen_print_loop(responses, stream, text_widget) print('End Speech to Text Streaming') if __name__ == '__main__': SpeechToTextApp().run()
実行結果は以下のようになりました。開始ボタンを押してから話し始めると、話したことが表示されていきます。文の途中のときは、その行の文が変わっていき、文末だと判断した場合に、新しい行から表示されています。そして、終了ボタンを押すと、リセットされています。
以上で、今回のテーマは終わりです。Speech to Textの部分に関しては、Googleにおんぶにだっこでしたが、さすがGoogleといった感じですね。
終わりに
今回は、実装がメインでしたが、音声認識のアルゴリズムも今後やっていきたいと思います。音声認識のアルゴリズムを勉強するならば、やはり以下の本機械学習プロフェッショナルシリーズの本が非常に参考になります。
")
参考Web
- Speech-to-Text: 自動音声認識 | Google Cloud
- Google Cloud Speech API を使った音声の文字起こし手順 - Qiita
- Python Kivyの使い方① ~Kv Languageの基本~ - Qiita