前回以下のエントリを書きました。そのエントリでは複数の機械学習のアルゴリズムの正答率を比較しましたが、1回の試行だけだったので複数回試行の結果でアルゴリズムを評価したいと思います。(*前回行った学習を複数回に拡張しただけです。)
dskomei.hatenablog.com
機械学習アルゴリズムの評価方法では有名なもの交差検証などがありますが、別の機会にアルゴリズムも踏まえて記載したいと思います。
本エントリではirisのデータに対して100回の試行による正答率の平均値と標準偏差で比較しています。実行結果は以下の表のとおりです。
学習用データ |
テスト用データ |
|||
|---|---|---|---|---|
モデル名 |
平均値 |
標準偏差 |
平均値 |
標準偏差 |
decision tree |
98% |
0.01 |
94% |
0.04 |
k nearest neighbor |
96% |
0.01 |
95% |
0.04 |
logistic regression |
96% |
0.01 |
93% |
0.04 |
random forest |
100% |
0.01 |
95% |
0.04 |
svm |
98% |
0.01 |
96% |
0.03 |
それぞれのモデルともテスト用データの正答率は、学習用データの正答率から3~4ポイントほど落ちています。ランダムフォレストは学習用データに対しては正答率が高いですが、テスト用データとの差分は一番大きいです。若干過学習しているかと思われます。SVMは学習用データとテスト用データとの差分が小さく、正答率も悪くないので今回においてはいいモデルのようです。
複数回試行の正答率を可視化する
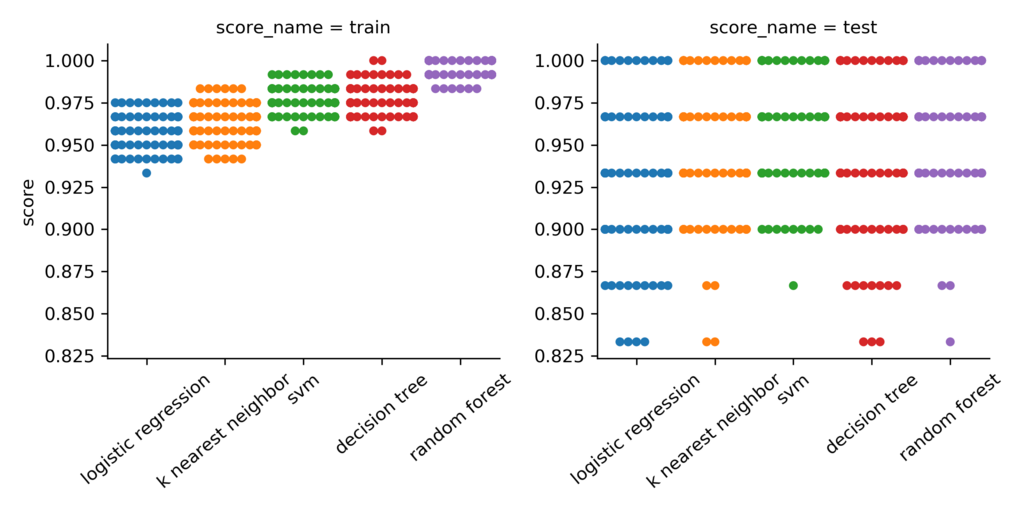
今回の100回の試行において、学習用データ/テスト用データの正答率を分けてすべてプロットしました。
どのモデルも学習用データの方が正答率が高いのがひと目で分かりますし、ランダムフォレストが過学習気味なのもわかります。
今回のコード
モデルの正答率集計の複数回試行に加えて、可視化のコードも載せています。グラフ用のライブラリとしては『seaborn』を使っています。簡単に使えてmatplotlibでは描けないグラフもできるのでぜひお試しください。
qiita.com
import pandas as pd import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import Pipeline import matplotlib.pyplot as plt import seaborn as sns # # データ部 # データを読み込んだ後、入力・出力データに分けている # data = datasets.load_iris() x_data = data.data y_data = data.target # # モデル設定部 # lr = Pipeline([('scl', StandardScaler()), ('clf', LogisticRegression(C=10))]) knn = Pipeline([('scl', StandardScaler()), ('clf', KNeighborsClassifier(n_neighbors=5))]) svm = Pipeline([('scl', StandardScaler()), ('clf', SVC(kernel='rbf', C=1.0))]) dc = DecisionTreeClassifier(criterion='entropy', max_depth=3) rf = RandomForestClassifier(criterion='entropy', n_estimators=10) models = [lr, knn, svm, dc, rf] model_names = ['logistic regression', 'k nearest neighbor', 'svm', 'decision tree', 'random forest'] ## 複数回の試行によりモデルを評価する score_datas = pd.DataFrame() for loop in range(100): x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2) for model_name, model in zip(model_names, models): model.fit(x_train, y_train) train_score = model.score(x_train, y_train) test_score = model.score(x_test, y_test) print('loop {}, Model : {:20}, train accuracy : {:3.0f}, test accuracy : {:3.0f}'.format(loop, model_name, train_score * 100, test_score * 100)) score_datas = pd.concat([score_datas, pd.DataFrame({'number':[loop], 'model_name':[model_name], 'score_name':['train'], 'score':[train_score]}), pd.DataFrame({'number': [loop], 'model_name': [model_name], 'score_name': ['test'], 'score': [test_score]})]) score_datas_sum = score_datas.groupby(['score_name', 'model_name']).agg({'score':[np.mean, np.std]}) print(score_datas_sum) fig = sns.factorplot(x='model_name', y='score', col='score_name', data=score_datas, kind='swarm') fig.set_xlabels('') fig.set_xticklabels(rotation=40) plt.tight_layout() plt.savefig('./images/scores.png', dpi=300) plt.show()
終わりに
今回は複数回試行によるモデルの評価を行いましたが、ハイパーパラメータの値によって結果が異なってきます。なので、ハイパーパラメータの調整を先に行った上でモデル間の比較を行う必要があります。次回はハイパーパラメータのチューニングによる結果の違いを見ていきたいと思います。